Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This document provides recommendations for the design and development of audio devices, including audio playback and audio input devices intended for use with Microsoft’s Speech Platform. The Speech Platform is used to power all of the speech experiences in Windows such as Voice Typing and Live Captions. The goal for this document is to enable ecosystem partners to build device with optimized audio experience with Microsoft technology.
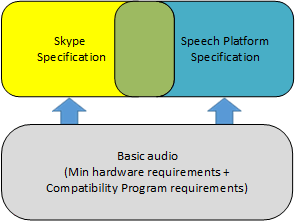
Minimum hardware requirements and the Windows Hardware Compatibility Program
The minimum hardware requirements and Windows Hardware Compatibility Program requirements are fundamental for creating Windows-compatible audio solutions. Although the programs are optional, it is highly recommended that audio products meet both sets of requirements to ensure basic audio quality.
For more detail on each:
See section 6.2.2 in Minimum hardware requirements
Scenario for optimizing multi-stream audio playback
Although Multi-streaming is no longer a requirement for the Windows 10 Desktop edition, it is highly recommended to have a minimum of two Digital-to-Analog Converters (DAC) to support Multi-streaming scenarios. If a single DAC (such as a Redirected headphone) is used, it is highly recommended to support audio volume control and status independently for each audio endpoint (such as e.g. integrated speakers, or a 3.5mm audio jack) so that user setting preferences can be retained.
Optimizing an audio solution for speech and communications
Once the audio solution meets both minimum hardware requirements and Windows Compatibility Program requirements, the audio solution will provide basic audio experiences in Windows. Depending on the targeted market segment, a device may support two additional optimizations: Speech Platform and Skype. Recommendations for both Speech Platform and Skype build upon the requirements for a basic audio experience. It would be a challenge to optimize for Speech Platform or Skype if the audio solution does not fully meet the basic requirements.
Note
Guidelines for Telephony and applications such as Skype will be supplemented to this topic when they are available.
Speech recognition in Windows
Device manufacturers are encouraged to integrate and tune speech enhancement processing into their device in order to optimize performance relative to the Speech Recognition test criteria.
For devices without integrated speech enhancement processing, Microsoft provides default processing in Windows. The speech enhancement processing from Microsoft does not need device-specific tuning by the IHV.
The Microsoft speech enhancement pipeline will be used if the audio driver does not expose a microphone geometry and audio signal processing for speech. To utilize third-party enhancements, the microphone geometry must be provided, support “speech” signal processing mode on the audio input, and ensure that the effects provided by the audio driver or its software APOs include at least noise suppression and echo cancellation.
Difference between Speech Recognition and Telephony
Many devices that target Speech Recognition functionality will also target Telephony usage. The similarities are evident – both scenarios use devices with microphones to pick up human speech, audio processing pipelines to remove noise from the environment and enhance human speech, and consuming applications that rely on a clear speech signal in order to understand the speech.
The differences lie in who or what consumes the speech signal. Telephony has a human consumer, for whom perceptual voice quality and speech intelligibility are paramount. Speech recognition has an algorithmic consumer, where machine learning trained on specific features of the speech signal determine what is recognized, and where those features do not necessarily align to perceptual norms.
Perceptual voice quality is often correlated with speech recognition accuracy, but this is not always the case. This document focuses on methods of evaluating and maximizing speech recognition accuracy. It is recommended to support the “speech” signal processing mode and to tune that mode specifically for speech recognition.
Passing Skype/Lync audio certification is a strong indicator of good device audio performance.
Audio device recommendations
The following sections cover recommendations for speech. To ensure a high quality speech experience, all devices should be tested against these performance requirements.
| Area | Type of guidance | Which devices should be tested |
|---|---|---|
| Device.SpeechRecognition | Provides the speech recognition performance requirements to ensure a high quality speech experience. | All devices should be tested against these performance requirements. |
| Device.Audio | Provides guidelines in order to function optimally with the host OS in terms of software interfaces, communication protocols, and data formats. | All devices should be tested against these guidelines. |
| Device.Audio.Acoustics | Provides recommendations and best practices for acoustics and related properties of device design. | Most relevant for devices that will use Microsoft’s speech enhancement processing. |
Device.SpeechRecognition
The following table summarizes Microsoft recommendations for target speech recognition accuracy for devices in various environments. All targets are in speech accuracy.
| Test | Description | Target | Recommendation |
|---|---|---|---|
| Device.SpeechRecognition.Quiet | An ideal environment with minimal ambient noise (noise floor < 35 dBA SPL) and no receive (echo path) noise. | Quiet <= 35 dBA SPL | 95% |
| Device.SpeechRecognition.AmbientNoise | Various levels and types of noisy environments, e.g. Café & Pub. | Ambient Noise @ DUT >= 57 dBA SPL | 90% |
| Device.SpeechRecognition.EchoNoise | Various levels and types of render playback scenarios (e.g. media playing). | Echo Noise @ LRP >= 70 dBA SPL | 90% |
Device.Audio
Recommendations in this section are made regarding the software and hardware interfaces, communication protocols, and data formats of the device. Devices intended to use speech recognition functionality must meet all Device.Audio Requirements.
| Name | Recommendation |
|---|---|
| Device.Audio.Base.AudioProcessing | Drivers must expose all audio effect via the FXStreamCLSID, FXModeCLSID, and FXEndpointCLSID APOs (or proxy APOs). The APOs must send an accurate list of effects that are enabled to the system when queried. Drivers must support APO change notifications and only notify the system when an APO change has occurred. |
| Device.Audio.Base.StreamingFormats | Speech recognition functions under all audio capture and render streaming formats defined in the StreamingFormats HLK, with the optimum being 16 kHz with 24-bit capture and mono render. |
| Device.Audio.Base.SamplePositionAccuracy | It is important that render and capture audio signals are both 1) sampled accurately and 2) time-stamped accurately. |
| Device.Audio.USB.USB | All USB audio input devices must properly set descriptor according to the USB.org device class spec. |
| Driver Guidelines | Roadmap for developing WDM Audio Drivers |
Device.Audio.Acoustics
Recommendations in this section are made regarding the acoustic and related properties of the device, such as microphone and loudspeaker placement, microphone responses, received noise from the device, and so on. Microphone selection, placement, integration, and array design are some of the most important factors to support quality speech recognition performance.
The recommendations and tests are relative to the signal before the speech enhancement processing but after microphone equalization and fixed microphone gain.
For more details about all of these recommendations, including recommended mic array geometries, see Microphone Array Geometry Descriptor Format.
| Name | Recommendation |
|---|---|
| Device.Audio.Acoustics.MicArray | Refer to Microphone Array Support in Windows. The audio driver must implement the KSPROPERTY_AUDIO_MIC_ARRAY_GEOMETRY property. Then the System.Devices.MicrophoneArray.Geometry property can be accessed via the Windows.Devices.Enumeration API. The USB audio driver will support this property for USB microphone arrays that have the appropriate fields set in the USB descriptor. |
| Microphone Array Descriptor | The device must describe its microphone type and geometry using the mic array descriptor. |
| Device.Audio.Acoustics.MicSensitivity | The Max recommendation is set to be able to support speech input levels considered to be “loud” and the Min recommendation is set to be able to support speech input levels considered to be “quiet.” |
| Device.Audio.Acoustics.MicIntegration | The microphones must be integrated to ensure a good acoustic seal between the microphone and the device chassis, and if appropriate, along the microphone porting tube. Minimize the acoustic noise and vibration between the system and the microphone. Two typical solutions are to use a rubber boot or a gasket. Whichever method is chosen check that the acoustic seal is sufficient across all production tolerances and over both environmental and lifetime changes. |
| Device.Audio.Acoustics.MicPlacement | Place the mic as far as possible from noise sources such as loudspeakers, fans, keyboards, hard drives, and the user’s hands, and as close as possible to the speaker’s mouth. |
| Device.Audio.Acoustics.MicSelfNoise | Use of a high quality microphone will minimize the microphone internal noise. Microphones with an SNR of at least 61 dB nominal is recommended for Standard and 63 dB for Premium. |
| Device.Audio.Acoustics.MicReceivedNoise | The two main sources of received noise are acoustic noise and electrical noise. Acoustic noise may come from outside the device, or be generated internally in the device due to fans, hard disks etc. The acoustic noise can also be transmitted through the device mechanics. Electrical noise can be minimized by using digital microphones rather than analog microphones. |
| Device.Audio.Acoustics.MicMagnitudeResponse | The Premium and Standard masks apply to all device tiers under Device.Audio.Acoustics.Bandwidth e.g. a device can have Standard bandwidth (narrow-band) and a Premium magnitude response within that band. |
| Device.Audio.Acoustics.MicPhaseResponseMatching | This recommendation ensures that the temporal relationship between signals received via microphone elements in an array is consistent with the physical geometry of the microphone elements in the array. |
| Device.Audio.Acoustics.MicDistortion | The distortion is recommended to be measured using SDNR (pulsed noise signal-to-distortion-and-noise ratio), although THD targets are also given. |
| Device.Audio.Acoustics.MicBandwidth | The sample rate of the capture signal is the primary factor in determining the effective bandwidth of the speech signal. As the speech platform uses 16 kHz acoustic models in the speech recognizer, a 16 kHz minimum sample rate is recommended. 300 Hz is the effective lower end of the speech recognizer, however 200 Hz is the recommended acoustical limit for devices also targeting voice communications. |
| Device.Audio.Acoustics.RenderDistortion | The distortion is recommended to be measured using SDNR (pulsed noise signal-to-distortion-and-noise ratio), although THD targets are also given. |
| Device.Audio.Acoustics.RenderPlacement | To enable the acoustic echo canceller to work well, the device speakers should be placed at a maximum distance from the microphones, or place directivity nulls towards loudspeakers. |
Requirements to enable a third-party enhancement pipeline
The following requirements are key to enable a third-party enhancement pipeline. These and other recommendations are covered in more detail in the following sections:
Microphone location reporting –explains how to implement a reporting structure for a mic array.
Speech mode supports:
How to register APOs for specific modes
Audio signal processing modes
Device.Audio.Base.Audioprocessing – Acoustic Echo Cancellation (AEC) and Nosie Suppression (NS) are required for third-party pipeline:
Implementing Audio Processing Objects
Audio Processing Object Architecture
Related resources
Windows Hardware Compatibility Program