Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
An Azure Service Fabric cluster is a resource you own, but it's partly managed by Microsoft. This article describes the options for when and how to update your Azure Service Fabric cluster.
Automatic versus manual upgrades
It's critical to ensure your Service Fabric cluster is always running a supported runtime version. Each time Microsoft announces the release of a new version of Service Fabric, the previous version is marked for end of support after a minimum of 60 days from that date. New releases are announced on the Service Fabric team blog.
Fourteen days before the expiry of the release your cluster is running, a health event is generated that puts your cluster into a Warning health state. The cluster remains in a warning state until you upgrade to a supported runtime version.
You can set your cluster to receive automatic Service Fabric upgrades as they are released by Microsoft, or you can manually choose from a list of currently supported versions. These options are available in the Fabric upgrades section of your Service Fabric cluster resource.
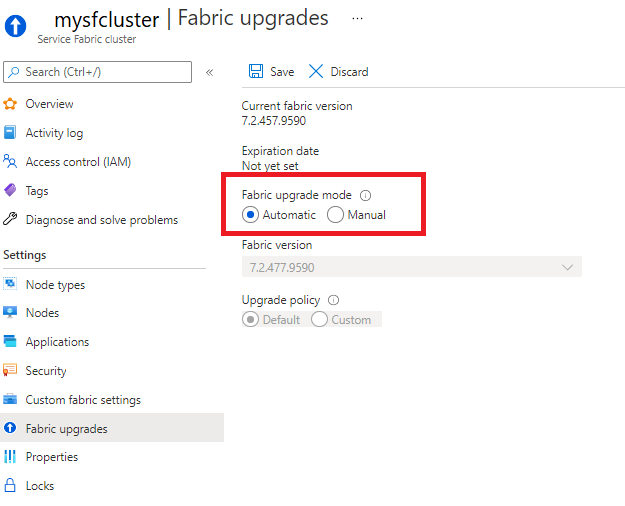
You can also set your cluster upgrade mode and select a runtime version using a Resource Manager template.
Automatic upgrades are the recommended upgrade mode, as this option ensures your cluster stays in a supported state and benefits from the latest fixes and features while also allowing you to schedule updates in a manner that is least disruptive to your workloads using a wave deployment strategy.
Note
If you change an existing cluster to automatic mode, the cluster will be enrolled for the next upgrade period starting with a new release. New releases are announced on the Service Fabric team blog. Per upgrade period the highest possible upgrade path is chosen, see supported versions. The manual upgrade mode triggers an immediate upgrade.
Wave deployment for automatic upgrades
With wave deployment, you can minimize the disruption of an upgrade to your cluster by selecting the maturity level of an upgrade, depending on your workload. For example, you can set up a Test -> Stage -> Production wave deployment pipeline for your various Service Fabric clusters in order to test the compatibility of a runtime upgrade before you apply it to your production workloads.
To opt in to wave deployment, specify one of the following wave values for your cluster (in its deployment template):
- Wave 0: Clusters are updated as soon as a new Service Fabric build is released. Intended for test/dev clusters.
- Wave 1: Clusters are updated one week (seven days) after a new build is released. Intended for pre-prod/staging clusters.
- Wave 2: Clusters are updated two weeks (14 days) after a new build is released. Intended for production clusters.
You can register for email notifications with links to further help if a cluster upgrade fails. See Wave deployment for automatic upgrades to get started.
Phases of automatic upgrade
Microsoft maintains the Service Fabric runtime code and configuration that runs in an Azure cluster. We perform automatically monitored upgrades to the software on an as-needed basis. These upgrades could be code, configuration, or both. To minimize the impact of these upgrades on your applications, they are performed in the following phases:
Phase 1: An upgrade is performed by using all cluster health policies
During this phase, the upgrades proceed one upgrade domain at a time, and the applications that were running in the cluster continue to run without any downtime. The cluster health policies (for node health and application health) are adhered to during the upgrade.
If the cluster health policies are not met, the upgrade is rolled back and an email is sent to the owner of the subscription. The email contains the following information:
- Notification that we had to roll back a cluster upgrade.
- Suggested remedial actions, if any.
- The number of days (n) until we execute Phase 2.
We try to execute the same upgrade a few more times in case any upgrades failed for infrastructure reasons. After the n days from the date the email was sent, we continue to Phase 2.
If the cluster health policies are met, the upgrade is considered successful and marked complete. This situation can happen during the initial upgrade or any of the upgrade reruns in this phase. There is no email confirmation of a successful run, to avoid sending excessive emails. Receiving an email indicates an exception to normal operations. We expect most of the cluster upgrades to succeed without impacting your application availability.
Phase 2: An upgrade is performed by using default health policies only
The health policies in this phase are set in such a way that the number of applications that were healthy at the beginning of the upgrade remains the same during the upgrade process. As in Phase 1, the Phase 2 upgrades proceed one upgrade domain at a time, and the applications that were running in the cluster continue to run without any downtime. The cluster health policies (a combination of node health and the health all the applications running in the cluster) are adhered to during the upgrade.
If the cluster health policies in effect are not met, the upgrade is rolled back. Then an email is sent to the owner of the subscription. The email contains the following information:
- Notification that we had to roll back a cluster upgrade.
- Suggested remedial actions, if any.
- The number of days (n) until we execute Phase 3.
We try to execute the same upgrade a few more times in case any upgrades failed for infrastructure reasons. A reminder email is sent a couple of days before n days are up. After the n days from the date the email was sent, we proceed to Phase 3. The emails we send you in Phase 2 must be taken seriously and remedial actions must be taken.
If the cluster health policies are met, the upgrade is considered successful and marked complete. This can happen during the initial upgrade or any of the upgrade reruns in this phase. There is no email confirmation of a successful run.
Phase 3: An upgrade is performed by using aggressive health policies
These health policies in this phase are geared towards completion of the upgrade rather than the health of the applications. Few cluster upgrades end up in this phase. If your cluster gets to this phase, there is a good chance that your application becomes unhealthy and/or loses availability.
Similar to the other two phases, Phase 3 upgrades proceed one upgrade domain at a time.
If the cluster health policies are not met, the upgrade is rolled back. We try to execute the same upgrade a few more times in case any upgrades failed for infrastructure reasons. After that, the cluster is pinned, so that it will no longer receive support and/or upgrades.
An email with this information is sent to the subscription owner, along with the remedial actions. We do not expect any clusters to get into a state where Phase 3 has failed.
If the cluster health policies are met, the upgrade is considered successful and marked complete. This can happen during the initial upgrade or any of the upgrade reruns in this phase. There is no email confirmation of a successful run.
Custom policies for manual upgrades
You can specify custom policies for manual cluster upgrades. These policies get applied each time you select a new runtime version, which triggers the system to kick off the upgrade of your cluster. If you do not override the policies, the defaults are used. For more, see Set custom polices for manual upgrades.
Other cluster updates
Outside of upgrading the runtime, there are a number of other actions you may need to perform to keep your cluster up to date, including the following:
Managing certificates
Service Fabric uses X.509 server certificates that you specify when you create a cluster to secure communications between cluster nodes and authenticate clients. You can add, update, or delete certificates for the cluster and client in the Azure portal or using PowerShell/Azure CLI. To learn more, read add or remove certificates
Opening application ports
You can change application ports by changing the Load Balancer resource properties that are associated with the node type. You can use the Azure portal, or you can use PowerShell/Azure CLI. For more information, read Open application ports for a cluster.
Defining node properties
Sometimes you may want to ensure that certain workloads run only on certain types of nodes in the cluster. For example, some workload may require GPUs or SSDs while others may not. For each of the node types in a cluster, you can add custom node properties to cluster nodes. Placement constraints are the statements attached to individual services that select for one or more node properties. Placement constraints define where services should run.
For details on the use of placement constraints, node properties, and how to define them, read node properties and placement constraints.
Adding capacity metrics
For each of the node types, you can add custom capacity metrics that you want to use in your applications to report load. For details on the use of capacity metrics to report load, refer to the Service Fabric Cluster Resource Manager Documents on Describing Your Cluster and Metrics and Load.
Customizing settings for your cluster
Many different configuration settings can be customized on a cluster, such as the reliability level of the cluster and node properties. For more information, read Service Fabric cluster fabric settings.
Note
For clusters using runtime versions before 10.0CU6, 10.1CU5, and 9.1CU12, if you modified or plan to modify any NTLM settings for the FileStoreService, expect some downtime while your cluster's nodes restart. This restart is tied to cleanup that occurs during the upgrade cycle.
This behavior is changed as of 10.0CU6, 10.1CU5, and 9.1CU12, and no node restarts should occur on clusters running these versions or later.
For more information on Service Fabric versioning, see the versions page.
Upgrading OS images for cluster nodes
Enabling automatic OS image upgrades for your Service Fabric cluster nodes is a best practice. In order to do so, there are several cluster requirements and steps to take. Another option is using Patch Orchestration Application (POA), a Service Fabric application that automates operating system patching on a Service Fabric cluster without downtime. To learn more about these options, see Patch the Windows operating system in your Service Fabric cluster.
Next steps
- Manage Service Fabric upgrades
- Customize your Service Fabric cluster settings
- Scale your cluster in and out
- Learn about application upgrades