Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
This article teaches you how to fail over a database linked between SQL Server and Azure SQL Managed Instance by using SQL Server Management Studio (SSMS) or PowerShell for the purpose of disaster recovery or migration.
Prerequisites
To fail over your databases to your secondary replica through the link, you need the following prerequisites:
- An active Azure subscription. If you don't have one, create a free account.
- Supported version of SQL Server with required service update installed.
- Link configured between your primary and secondary replica.
- You can fail over the link by using Transact-SQL starting with SQL Server 2022 CU13 (KB5036432).
Stop workload
If you're ready to fail over your database to the secondary replica, first stop any application workloads on the primary replica during your maintenance hours. This enables database replication to catch up on the secondary so you can fail over to the secondary without data loss. Ensure your applications aren't committing transactions to the primary before failing over.
Check replication lag
It's important that the secondary replica catches up to the primary replica before performing a planned failover. Planned failover can time out and fail if the secondary replica lags far behind the primary replica.
Use the following T-SQL query on both SQL Server and SQL Managed Instance to monitor replication lag between the replicas:
-- Execute on SQL Server and SQL Managed Instance
USE master
DECLARE @link_name varchar(max) = '<DAGname>'
SELECT
ag.name [Link name],
ars1.role_desc [Link role],
ars2.connected_state_desc [Link connected state],
ars2.synchronization_health_desc [Link sync health],
drs.secondary_lag_seconds [Link replication latency (seconds)]
FROM
sys.availability_groups ag
JOIN sys.dm_hadr_availability_replica_states ars1
ON ag.group_id = ars1.group_id
JOIN sys.dm_hadr_availability_replica_states ars2
ON ag.group_id = ars2.group_id
JOIN sys.dm_hadr_database_replica_states drs
ON ars2.replica_id = drs.replica_id
WHERE
ag.is_distributed = 1 AND ag.name = @link_name AND ars1.is_local = 1 AND ars2.is_local = 0
GO
If the replication lag is high, wait for the secondary replica to catch up with the primary replica. You might need to perform additional troubleshooting steps if the lag persists, such as improving link network throughput between the two instances, or increasing resource capacity on the secondary replica.
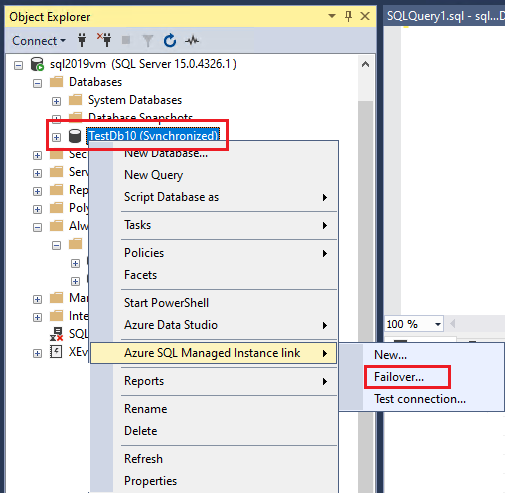
Fail over a database
You can fail over a linked database by using Transact-SQL (T-SQL), SQL Server Management Studio, or PowerShell.
You can fail over the link by using Transact-SQL starting with SQL Server 2022 CU13 (KB5036432).
To perform a planned failover for a link, use the following T-SQL command on the primary replica:
ALTER AVAILABILITY GROUP [<DAGname>] FAILOVER
To perform a forced failover, use the following T-SQL command on the secondary replica:
ALTER AVAILABILITY GROUP [<DAGname>] FORCE_FAILOVER_ALLOW_DATA_LOSS
Important
After executing a planned failover, the replication mode is set to asynchronous.
Fail over multiple databases
If you plan to fail over multiple databases from instances on the same server, for optimal performance and predictability, fail over 8 databases per instance at a time. For example, if you have 10 instances with 32 linked databases each, fail over 8 databases at a time from each instance, and repeat the process until all databases are failed over.
View database after failover
For SQL Server 2022, if you chose to maintain the link, you can check that the distributed availability group exists under Availability Groups in Object Explorer in SQL Server Management Studio.
If you dropped the link during failover, you can use Object Explorer to confirm the distributed availability group no longer exists. If you chose to keep the availability group, the database will still be Synchronized.
Clean up after failover
Unless Remove link after successful failover is selected, failing over with SQL Server 2022 doesn't break the link. You can maintain the link after failover, which leaves the availability group, and distributed availability group active. No further action is needed.
Dropping the link only drops the distributed availability group, and leaves the availability group active. You can decide to keep the availability group, or drop it.
If you decide to drop your availability group, replace the following value and then run the sample T-SQL code:
<AGName>with the name of the availability group on SQL Server (used to create the link).
-- Run on SQL Server
USE MASTER
GO
DROP AVAILABILITY GROUP <AGName>
GO
Inconsistent state after forced failover
Following a forced failover, you might encounter a split-brain scenario where both replicas are in the primary role, leaving the link in an inconsistent state. This can happen if you fail over to the secondary replica during a disaster, and then the primary replica comes back online.
To resolve this issue, see Fix split-brain scenario.
Related content
To use the link:
- Prepare environment for the Managed Instance link
- Configure link between SQL Server and SQL Managed instance with SSMS
- Configure link between SQL Server and SQL Managed instance with scripts
- Migrate with the link
- Best practices for maintaining the link
- Troubleshoot issues with the link
To learn more about the link:
For other replication and migration scenarios, consider: