Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Question
Thursday, May 23, 2019 12:59 AM
Hi,
I have a SQL Azure database where i have enabled automatic tuning in SQL Azure, so Azure creates and deletes indices as it feels necessary. I like this as my level of knowledge on idices is not great.
Now, i have a table that has started to cause deadlocks and i dont know why. It is a simple table that has a status column, and we use it as like a queue, we add rows in a pending state, then we select a pending task and update it to in progress, and once complete we update the status to complete. There are constantly inserts and updates happening on the table.
Below are the details of the deadlock. Can anyone explain to me in reasonable simple terms what is causing my deadlock. They are two update quieres so i think one should just block the other, and wait until the other is finished and then continue. So i assume it is the index that is causing the deadlock, but i dont know anything beyond that. Really appreciate any help.
<deadlock>
<victim-list>
<victimProcess id="process13ab3b22ca8" />
</victim-list>
<process-list>
<process id="process13ab3b22ca8" taskpriority="0" logused="0" waitresource="KEY: 5:72057594049658880 (e10addd384fe)" waittime="449" ownerId="493079967" transactionname="UPDATE" lasttranstarted="2019-05-23T00:09:38.330" XDES="0x13abade4428" lockMode="U" schedulerid="1" kpid="61712" status="suspended" spid="132" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2019-05-23T00:09:38.330" lastbatchcompleted="2019-05-23T00:09:38.337" lastattention="1900-01-01T00:00:00.337" clientapp=".Net SqlClient Data Provider" hostname="RD0003FF21FC37" hostpid="11172" loginname="loginname" isolationlevel="read committed (2)" xactid="493079967" currentdb="5" currentdbname="databasename" lockTimeout="4294967295" clientoption1="673185824" clientoption2="128056">
<executionStack>
<frame procname="e1a95efe-ec78-4847-b0cb-f14d3a257103.tb.TaskSchedulerItem_Update_PendingItemsToCancelled_ByTaskSchedulerIdByReferenceId" queryhash="0xad84b250c4c13ec3" queryplanhash="0x879b9bca9cf428df" line="10" stmtstart="376" stmtend="814" sqlhandle="0x03000500ddcd7a0d01462f01baa9000001000000000000000000000000000000000000000000000000000000">
Update [TaskSchedulerItem]
Set ItemStatus='CANCELLED',
ItemStatusDescription='CANCELLED DUE TO NEW ITEM REPLACING'
Where TaskSchedulerId=@TaskSchedulerId
and ItemReferenceId=@ItemReferenceId
and ItemStatus='PENDING </frame>
</executionStack>
<inputbuf>
Proc [Database Id = 5 Object Id = 226151901] </inputbuf>
</process>
<process id="process13ab712f468" taskpriority="0" logused="376" waitresource="KEY: 5:72057594053591040 (c501f23cb8fa)" waittime="449" ownerId="493079974" transactionname="UPDATE" lasttranstarted="2019-05-23T00:09:38.437" XDES="0x13abf698428" lockMode="X" schedulerid="2" kpid="114596" status="suspended" spid="129" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2019-05-23T00:09:38.367" lastbatchcompleted="2019-05-23T00:09:38.370" lastattention="1900-01-01T00:00:00.370" clientapp=".Net SqlClient Data Provider" hostname="RD00155D31D49D" hostpid="16940" loginname="loginname" isolationlevel="read committed (2)" xactid="493079974" currentdb="5" currentdbname="databasename" lockTimeout="4294967295" clientoption1="673185824" clientoption2="128056">
<executionStack>
<frame procname="e1a95efe-ec78-4847-b0cb-f14d3a257103.tb.TaskSchedulerItem_Select_NextToProcess" queryhash="0xec04ed9404b13746" queryplanhash="0x54e2b3a709c1a4eb" line="51" stmtstart="2460" stmtend="3644" sqlhandle="0x03000500f0fe481b961a020153aa000001000000000000000000000000000000000000000000000000000000">
UPDATE [TaskSchedulerItem]
SET
ItemStatus = 'IN PROGRESS',
ItemStatusDescription = 'IN PROGRESS',
DateLastUpdated = @CurrentDateTime
output inserted.TaskSchedulerId,inserted.TaskSchedulerItemId, inserted.ItemReferenceId,inserted.ItemStatus,inserted.ItemStatusDescription, inserted.DateCreated, inserted.DateLastUpdated, inserted.FailureCount
Where TaskSchedulerItemId = @TaskSchedulerItemId
and
(
ItemStatus in ('PENDING','FAILED')
or
(ItemStatus = 'IN PROGRESS' AND DateLastUpdated<DATEADD(MINUTE,-1,@CurrentDateTime))
)
and TaskSchedulerId=@TaskSchedulerI </frame>
</executionStack>
<inputbuf>
Proc [Database Id = 5 Object Id = 457768688] </inputbuf>
</process>
</process-list>
<resource-list>
<keylock hobtid="72057594049658880" dbid="5" objectname="e1a95efe-ec78-4847-b0cb-f14d3a257103.tb.TaskSchedulerItem" indexname="PK_TaskSchedulerItem" id="lock13995619000" mode="X" associatedObjectId="72057594049658880">
<owner-list>
<owner id="process13ab712f468" mode="X" />
</owner-list>
<waiter-list>
<waiter id="process13ab3b22ca8" mode="U" requestType="wait" />
</waiter-list>
</keylock>
<keylock hobtid="72057594053591040" dbid="5" objectname="e1a95efe-ec78-4847-b0cb-f14d3a257103.tb.TaskSchedulerItem" indexname="nci_wi_TaskSchedulerItem_10D8AC902621242A89D6" id="lock139c6032880" mode="U" associatedObjectId="72057594053591040">
<owner-list>
<owner id="process13ab3b22ca8" mode="U" />
</owner-list>
<waiter-list>
<waiter id="process13ab712f468" mode="X" requestType="wait" />
</waiter-list>
</keylock>
</resource-list>
</deadlock>
David
All replies (11)
Thursday, May 23, 2019 3:08 AM
It looks like you have a compound PK on the table, which I guess is the cause of it taking key locks rather than row locks, and the key locks are more prone to deadlocks.
Does the logic require updating many rows at a time, or just single rows? If so you could move the PK to an identity field, have simpler predicates, and probably eliminate the deadlocks that way.
Otherwise it will probably require trying hints or something to resolve.
SQL Server is often twitchy about doing anything with compound keys.
Josh
Thursday, May 23, 2019 4:55 AM
Hi Josh,
Thank you for the comment.
I dont think I do have a compound PK. Can you see my table in the image.
To answer your question. The logic is simple, it is a queue that we add rows to for something to be done, but before we add a row, we update any previous rows that haven't been processed yet for that same item to cancelled, so that when the new item that gets inserted iit s the only one that gets processed. So we do an update all to cancelled where itemreferenceid=xxxx. And then we do an insert of the new row to be processed.
They are the two quieres that you are seeing above. One is updating a number of rows to cancelled, and then the next query runs to update one row to in progressed. Please note these queries are not running in sequential order, two different threads are running them.
With this information what do you think?
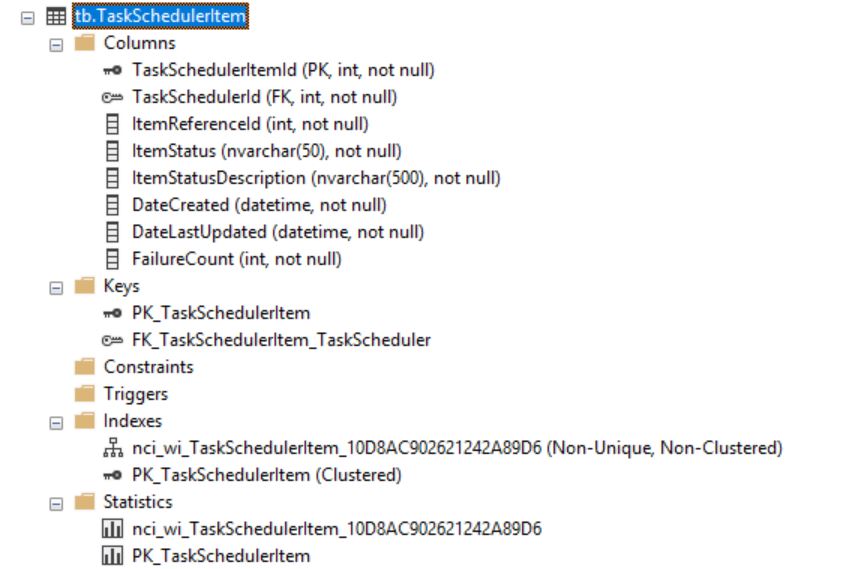
David
Thursday, May 23, 2019 9:32 PM
The table hsa a clustered index and a non-clustered index which includes the column ItemStatus.
One process has located a row to update thrugh the clustered index and has updated the data page. It now wants to update the index page with the new value of ItemStatus.
The other process has located the same row through the non-clustered index and taken an Update lock on that row in the index. An Update lock is a read-lock that only can be held by one process. This Update lock blocks the first process. The second now wants to take an Update lock also on the data page, but is bloccked by the first process.
That is your deadlock.
Erland Sommarskog, SQL Server MVP, esquel@sommarskog.se
Thursday, May 23, 2019 10:47 PM
Hi Erland,
Thank you for your comment.
If i understand your comment correctly, does this mean that to avoid deadlocks, if a table has a clustered index (which all of mine do), i should never create a non clustered index on a column that gets updated by update statements. So i should only ever create indexes on columns that don't get their values changed by an update statement, or else two queries updating the same row at the same time will cause a deadlock. I thought one update statement should just wait for the other update statement, but apparently not.
It is just i am surprised how there are not deadlocks happening all the time on all my tables, but this particular deadlock is happening on a daily basis, and i cant believe that it is so frequent.
Am I understanding your comment correctly?
Thank You
David
David
Thursday, May 23, 2019 11:44 PM
David,
OK, the logic is clear now.
But why would one SPID be cancelling an item at the same time another SPID is marking it busy? That's just asking for trouble. Shouldn't the cancel complete first?
I think Erland is just explaining the deadlock, it's common enough to include the PK in nonclustered secondary keys and in most cases shouldn't cause any more trouble than fifty other things. I mean, Azure wouldn't create a silly index, would it? (LOL) At least it wouldn't do something especially likely to cause trouble. We like to hope ...
Josh
Friday, May 24, 2019 4:26 AM
Hi Josh,
You are correct, the cancel should complete first, and that is what i want to happen. This is why i do not understand the deadlock. I will give you the logic.
We have a web app where a user gets sent an email when they update their profile, and they could make many updates which would trigger many emails (many rows in this table). We don't want to send the user many emails, we just want to send them one, so every time a user updates their profile, it first cancels any unsent emails (updates the rows to cancelled that have not yet been processed by the worker role), and schedules a new email to be sent which will be the only email the user gets.
Here is the logic
Web App:
- A user logs in to the web app and makes a change to their profile. This causes an update on the table setting everything to be cancelled for that user and then inserts a new row with status pending.
Worker Role:
- Every 10 seconds we have a worker role that updates any rows that are status Pending to In Progress, and then sends the email, and then updates the row to completed.
So what is happening here, is the deadlock is happening between the worker role, and the web app. The web app is cancelling any unsent emails at the same time that the worker role is trying to update the same record to in progress. I thought SQL Server should just work, that which every query got their first would be the one to update to the row. So like you said, should the cancel not finish first, I agree with you, if the cancel started the update first it should do the update, then the worker role will not pick it up because the status is cancelled.
Does this make sense? With this information what would be your suggestion for resolving the issue.
I also dont understand your comment "it's common enough to include the PK in nonclustered secondary keys"
What are secondary keys?
David
Friday, May 24, 2019 8:58 AM
If i understand your comment correctly, does this mean that to avoid deadlocks, if a table has a clustered index (which all of mine do), i should never create a non clustered index on a column that gets updated by update statements.
As Josh pointed out, this conclusion is too far-reaching. If you don't have two processes updating the same row from different conditions, the risk for deadlocks is small.
I also dont understand your comment "it's common enough to include the PK in nonclustered secondary keys"
What Josh is referring to is that when you create a non-clustered index, the key column(s) of the clustered index will always be included in that index, because they are used as rwo locator. But this is not very relevant to the problem. You could still have the same deadlock if all indexes were non-clustered.
Thanks for the detailed description of the processes involved! This helps when trying to suggest solutions, although there are still more details I would need to know to say what is the best solution, so I will outline a few.
One is have the worker role issue SET DEADLOCK_PRIORITY LOW, to make sure that this process is always the deadlock victim. We want this for two reasons: 1) This is a background process and no user is suffering. 2) From your description it is clear that the worker should wait for a cancellation to get through. The work capture the error with TRY-CATCH and rerty if the error is 1205.
An improvement of this is to let the worker say
SET LOCK_TIMEOUT 0
This means that if the worker is blocked, it gets the error 1222. If this happens, it should wait for some hundred ms and try again. The advantage with this is that the user process will not be delayed. (It can take up to five seconds until SQL Server detects the deadlock) I should clarify that 100 ms is an arbitrary number.
But if the system is busy the worker may be blocked all the time, and mails are not sent. An alternative is to just read the PENDING/FAILED rows into a temp table, using the READPAST hint so that you are not blocked by rows being updated. Then you loop over the temp table, and send the mail one by one. Before sending the mail, you need to check that the status is still the same, and you should update the row, since now it is too late to cancel.
Erland Sommarskog, SQL Server MVP, esquel@sommarskog.se
Friday, May 24, 2019 3:40 PM
David,
It is not always true, as you can see, that the first query in is the first to finish.
If the first to start runs a long time a second query may start working right in the middle, and interfere with things. Blocking will usually occur and they can run together, but sometimes their timeslices get interleaved and they interfere and deadlock. The default behavior of a query in SQL Server is atomic as a transaction - but NOT atomic as an execution. BOL never makes that clear. If you have an update with a where clause, you have to figure the where clause will run, then the timeslice will end, then the update will begin - at least a two-phase execution.
You can try adding a hint, "with (updlock)" to both updates, that might be a quick fix.
Though in fact, you might even want to try "with (tablockx)" because that makes more sense for managing a queue. Then I think you will get blocking and the FIFO you expected.
Josh
ps - you don't have a huge volume of transactions in this thing, do you? I'm pretty surprised you have a problem in the first place. How large is your queue table? Is it holding the last ten years history, making searches slow? You should probably keep a separate history table, that would help, too.
Monday, June 3, 2019 9:47 PM
Hi Josh,
Thank you for that, it helps alot, but i do not understand how with (updlock) or with (tablockx) would help the situation. Because as far as i can read online those commands will help me get a row lock or a table which is fine, but i think we are saying that it is the index here that is causing the problem. Because the deadlock is being caused by two update quieres. This in itself cannot cause a deadlock as far as i understand. So the issue is that both are trying to update the index, but one has the index locked before the other gets to it which is causing the deadlock. I think we are clear that deleting the index wold resolve the issue, but cause performance issues.
So can you explain to me how a row lock or table lock would help this situation? As an update on a row should be doing this anyway as natural behaviour in sql server?
To answer your question, we keep about 3 months of history in the table, there are inserts going into this table every 20 or 30 seconds. And before every insert, the updating of older rows to cancels happens. Each query runs in less than a second, so i think performance is not an issue causing this. The table has about 900,000 rows in it at any one time. We delete older rows every couple of weeks.
Thanks again for the help.
Thank You
David
David
Tuesday, June 4, 2019 2:45 AM
David,
I've already explained it (briefly) above - statements are not normally atomic. They can get tangled up.
Putting these hints on prevents the tangles.
It turns deadlocks, that are problems, into blocks, which are OK at the cost of a short delay.
Easy to try!
How about you keep ONE DAY's worth of data in the action table, this also would probably fix the problem, copy all rows out at the end of each working day. But to be safe do both: put on the hint *and* cut that table down as far as you can. Frankly, cutting it down to an hour, or removing rows (copying to archive) as soon as marked complete, would be best. In fact do not even update them here, in one transaction insert them into the new table marked as complete, and then delete them from the action table.
Josh
ps - of course doing that copy and delete would require app changes, so do the hints now, change the app later - and when the table is minimized you may not even need the hints anymore - though they still won't really hurt anything, cheap insurance.
Tuesday, June 4, 2019 9:27 AM
Thank you for that, it helps alot, but i do not understand how with (updlock) or with (tablockx) would help the situation. Because as far as i can read online those commands will help me get a row lock or a table which is fine, but i think we are saying that it is the index here that is causing the problem. Because the deadlock is being caused by two update quieres. This in itself cannot cause a deadlock as far as i understand. So the issue is that both are trying to update the index, but one has the index locked before the other gets to it which is causing the deadlock.
The point with the hints, or the ideas I suggested, is that they introduce serialization so that only one update occurs at a time. Rather than the two process coming from different angles to update the same row and then colliding with each other, the one that comes second is now stopped at the gate.
Erland Sommarskog, SQL Server MVP, esquel@sommarskog.se